Functionality of the RDB archiving
Data model
The RDB Archive Manager passes the value changes from WinCC OA to specific tables in the RDB. The allocation of what value is written to what table is defined in the same way as for the Value Archive by means of the _archive config. In this way, a unique allocation is defined between a data point element in WinCC OA and a table in the RDB that is responsible for archiving it.
The organization of the tables in the DB itself is divided into tables for values (values can be stored in different value/archive groups, see diagram at the end of this page) and a table for alerts (there is only one table for alerts in Oracle). Two tables are used in each value/archive group to manage values of the Array type (for example, WinCC OA data type dyn_float) and the remaining data types in the other table (for example, WinCC OA data type int) separately from each other.
The WinCC OA data types "blob", "struct", "langString", "dpIdentifier" and their array forms (see Data type ranges), as well as the control data type "dyn_dyn" (see Data types) are not supported by the RDB Archive Manager.
Grouping the tables into values and alerts caters for the fact that the type and expected number of data will obviously be different in the two groups.
Actual archiving is not performed in the input tables themselves in Oracle. These tables only store the WinCC OA values that have an archive config. Every input table has a child table that logs and thus archives value changes from the input tables.
An input table in Oracle therefore contains all current values of data point elements assigned to it and therefore the current process image as well, albeit only for such data that has been flagged for archiving. Values in the input table are constantly being overwritten. The child table receives the values from the input table and the value changes are stored but not overwritten.
Data flow of RDB write access
WinCC OA UI (or WinCC OA driver) > WCCILevent > WCCILdata > WCCOArdb > libSQLAPI.dll > RDB
Data flow of RDB read access
Version 1 (without config entry):
WinCC OA UI (or WinCC OA driver) > WCCILevent > WCCILdata > WCCOArdb > BasicRDBArchive.dll > libSQLAPI.dll > RDB
Version 2 (with config entry):
WinCC OA UI (or WinCC OA driver) > CtrlRDBArchive.dll > BasicRDBArchive.dll > libSQLAPI.dll > RDB
Data flow when reading compressed values from RDB
WinCC OA UI (or WinCC OA driver) > CtrlRDBCompr.dll > BasicRDBArchive.dll > libSQLAPI.dll > RDB
Archiving, archive groups, tablespaces, naming convention
Therefore, writing to the child tables (=archive sets) of the input tables triggers the actual archiving process. Child tables that are being written to are referred to as "current", comparable to a current archive set in the Value Archives. And, just as there, the current table is closed based on quantity or time. It is then referred to as "online" and is replaced by a new "current" table.
As long as a table has "online" or "current" status, it may be read or written to using WinCC OA or an external evaluation tool. However, tables can also have "offline" status. Then, they can no longer be accessed ("unhitched", there is only one entry in Oracle indicating that this table exists) but the physical file is already in the backup directory (you can therefore no longer access an offline archive via the Oracle database). This status is required so that tables can be backed up (= relocated to an external medium). Backed-up tables are then given the "backup" status and now only exist on the backup medium (the associated offline table is deleted on the Oracle server). Of course, you can restore these tables again to make them available for queries. Before a table is backed up, the system searches for the most recent value of each data point element in it and writes them to the oldest remaining associated table as "dregs". Dregs ensure that the values are not completely lost. If a value does not occur for a long time and is backed up again and again, this value would be lost.
It is not allowed to set an Archivefile to OFFLINE between ONLINE and CURRENT Archivefiles. It is strongly recommended to set only the oldest Archivefile to OFFLINE.
If Oracle Standard Edition is used, tablespaces are not deleted, but only the corresponding data files are copied for backup. Otherwise the tablespaces could not be restored anymore.
All related tables ("current", "online", "offline") form an archive group. In this case, the two input tables (one for the "normal" values and one for the array data types) and the child tables responsible for actual archiving all belong together. The smallest possible content of an archive group is thus four tables, 2 input tables and 2 child tables with "current" status. However, an archive group can of course also contain an additional and variable number of "online" and "offline" tables.
The allocation of Oracle tables to archive groups is on the basis of a unique identifier with a maximum of seven digits. This name is used to identify the group and also features as part of the table name. Looking at the default tables (EventLastVal and EventLastValValues with EventHistory and EventHistoryValues, and AlertLastVal and AlertLastValValues with AlertHistory and AlertHistoryValues), it can be seen that the first four tables are obviously allocated to a group called "Event" and the other four tables to a group called "Alert". These are the read views. The individual tables are called for example, EventHistory_00000021 (see diagram below).
Settings for table change, backup time and so on are specified per archive group. If an archive set change is performed in an archive group (the "current" tables are closed and become the latest online tables, a new "current" table pair is created), every new table pair is labelled with a unique 8-digit number. This number is appended to the name of the new table as a suffix. Also, a separate tablespace is created for each new table pair.
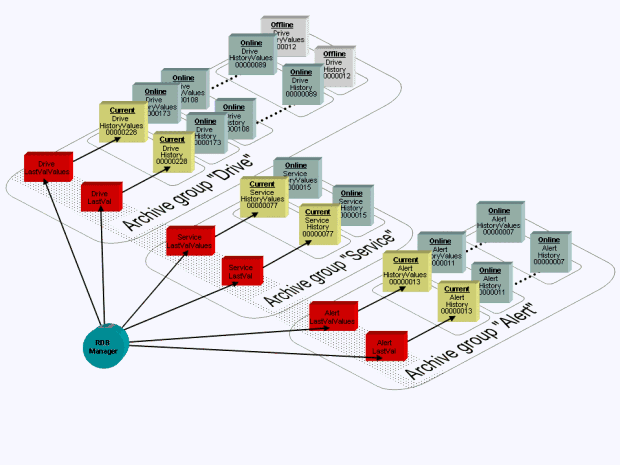
Once each archive set is stored in its own tablespace, the backup or restore task can be performed. The only thing to do is back up the tablespace from Oracle and relocate it.
The names of the tablespaces are derived from the names of the archive groups. Tablespaces that contain the archive group table pairs are named the same as the archive group and additionally include the user name as prefix as well as the archive number as suffix (for example, tablespace Schmidt_Antriebe_00000228.DBF contains the archive number 228 of the archive group Antriebe with the tables AntriebeHistory_00000228 and AntriebeHistoryValues_00000228).
A user name can contain up to 13 characters.
The tablespace containing all other tables required for managing the archive is named the same as the user logged into Oracle, prefixed with "TS". So if you specify during RDB setup that a user called "Operator" will log into Oracle, the tablespace for the other tables will be called "TS_Operator".

