BufferToDiskMax
BufferToDiskMax wird dann eingesetzt, wenn der Schutz der Datenblöcke vor Datenverlust höchste Priorität hat.
Bei BufferToDiskMax werden Daten, die im Hauptspeicher gepuffert werden, auch zugleich auf der Festplatte gepuffert, wodurch eine doppelte Absicherung zustande kommt. Das Verzeichnis auf der Festplatte ist frei wählbar (siehe Config-Eintrag "bufferToDiskDir").
Pufferverhalten abhängig vom Verbindungsstatus
Im Folgenden wird das Verhalten des Pufferprozesses mit BufferToDiskMax abhängig vom aktuellen Verbindungsstatus zur DB beschrieben.
Normalbetrieb
Ist die Verbindung zur Datenbank vorhanden, werden die Datenblöcke für einen kurzen Zeitraum im Hauptspeicher und auf der lokalen Festplatte gepuffert und sofort in die Datenbank geschrieben.
Verbindung zwischen RDB und Datenbank wurde unterbrochen
Solange im Hauptspeicher genügend Platz vorhanden ist, werden die Daten im Hauptspeicher und auf der Festplatte gepuffert. Wird das Limit an Speicherplatz im Hauptspeicher erreicht, werden neue Daten nur auf der Festplatte gepuffert.
Verbindung zwischen RDB und Datenbank wurde wieder hergestellt
Die gepufferten Datenblöcke werden in der Reihenfolge in die DB geschrieben, in der sie auch gepuffert wurden. Das bedeutet, dass zuerst die ältesten Daten aus dem Hauptspeicher und erst danach die neuen Daten von der lokalen Festplatte in die Datenbank geschrieben werden.
Absturz des RDB Managers
Insofern für den Absturz nicht ein Defekt in der Festplatte zuständig war, können alle Daten von der lokalen Festplatte ausgelesen werden (kein Datenverlust).
Neustart des RDB Managers nach Absturz
Wurde nach dem RDB Neustart die Verbindung zur Datenbank ebenso wieder hergestellt, so wird überprüft, ob die Datenblöcke auf der Festplatte vorhanden sind. Ist das der Fall, so werden die in die Datenbank geschrieben.
Handelt es sich dabei um ein Absturz eines redundanten RDB, werden auf jedem System die Daten gepuffert. Damit die Daten später nicht doppelt in die Datenbank geschrieben werden, überprüft der passive RDB den ersten und den letzten Eintrag im Block. Wenn beide bereits in der Datenbank vorhanden sind, werden diese nicht wieder in die Datenbank geschrieben. Wenn einer der Einträge fehlt, wird der Block in die Datenbank geschrieben. Der Ablauf wird nur ausgeführt, wenn der RDB passiv ist und beim Start des RDB Blöcke auf der Festplatte vorhanden waren. Dieser Modus wird solange ausgeführt, bis alle - beim Start des RDB vorhandenen - Disk-Puffer abgearbeitet wurden.
Wird die RDB ohne Datenbankverbindung neu gestartet, so werden die Datenblöcke nach dem gleichen Prinzip wie bei einer Verbindungsunterbrechung gepuffert, bis die Verbindung wieder hergestellt wird.
Indikator des Pufferverhaltens
In der folgenden Abbildung wird Ihnen das Zusammenspiel zwischen Hauptspeicher und lokaler Festplatte bei der Datenübergabe veranschaulicht. Im internen Datenpunkt bufferToDiskIndicator können Sie einsehen, welches Pufferverhalten zum aktuellen Zeitpunkt eingesetzt wird.
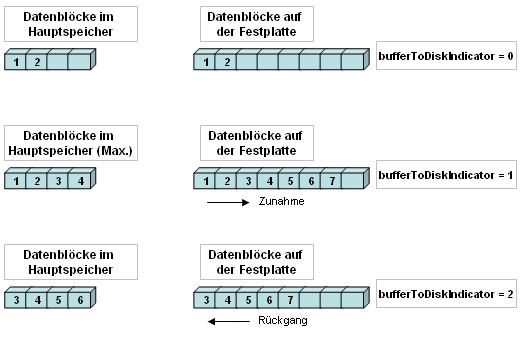
bufferToDiskIndicator = 0
Datenblöcke werden im Hauptspeicher und auf der Festplatte gepuffert. Sobald Blöcke im Hauptspeicher wieder frei werden, wird der Indikator auf 0 gesetzt. Falls weniger Blöcke auf der Festplatte vorhanden sind, als freie Blöcke im Hauptspeicher, wird der Indikator ebenfalls auf 0 gesetzt.
Ursache: stabile Datenverbindung; keine Notwendigkeit der Speicherung der Daten auf der Festplatte
bufferToDiskIndicator = 1
Datenblöcke, die wegen Speichermangel nicht mehr im Hauptspeicher gepuffert werden können, werden auf nur noch der Festplatte gepuffert.
Ursache: Datenflut; DB-Verbindungsunterbrechung
bufferToDiskIndicator = 2
Gepufferte Datenblöcke werden chronologisch in die Datenbank geschrieben.
Ursache: DB-Verbindung wurde wieder hergestellt

